Le corpus oral des dialectes des Pays-Bas méridionaux conserve les voix du passé
Depuis les années 1960, des linguistes de l’UGent constituent un trésor sonore unique: des centaines d’heures d’enregistrements de dialectes parlés en Flandre et dans le nord de la France. Ces bandes sonores sont désormais accessibles via une base de données en ligne. Des premières cassettes enregistrées dans les foyers au début des années 1960 jusqu’à la numérisation récente de ces voix d’un autre temps, comment est né et s’est développé ce corpus?
Le groupe de néerlandais du Département de linguistique de l’UGent se distingue par sa longue tradition de recherche dialectologique. Celle-ci a généré, au fil des siècles, de riches collections de données dialectales. Jusque dans les années 1950, les collections étaient principalement de nature écrite. Les chercheurs demandaient aux locuteurs comment ils exprimeraient certains mots ou phrases dans leur dialecte, puis notaient leurs réponses.
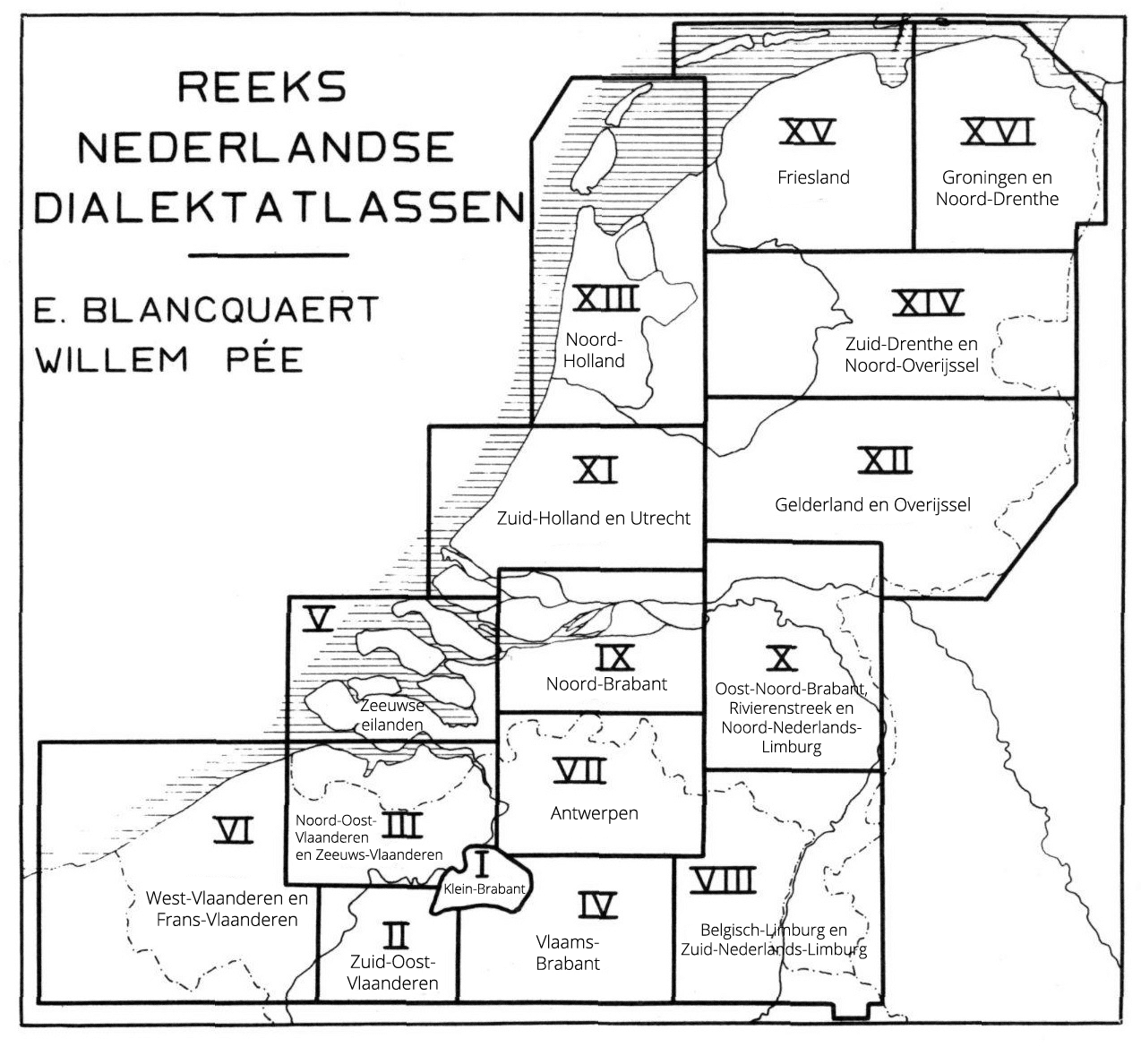
Aujourd’hui, une grande partie de ce matériel écrit a été numérisée. La transcription phonétique de milliers de phrases dialectales appartenant aux atlas des dialectes néerlandais (Reeks Nederlandse Dialectatlassen) est consultable en ligne, et il est possible d’effectuer des recherches partielles à sur ces transcriptions. De même, le dictionnaire des dialectes flamands (Woordenboek van de Vlaamse Dialecten) peut être consulté sous forme numérique.
Dans les années 1960, le magnétophone est devenu un instrument populaire et abordable. Cela a rendu possible les enregistrements de la langue dialectale parlée. L’un des principaux avantages des enregistrements réside dans la facilité à capter le langage spontané, permettant ainsi l’étude des «dialectes à l’état sauvage». Dans ce contexte, une collection audio unique a vu le jour à l’UGent dès les années 1960. Les voix de centaines de locuteurs de dialectes néerlandais du XXe siècle, originaires de Flandre et du nord de la France, y ont été enregistrées pour la postérité.
Cette collection a pourtant été peu exploitée pendant longtemps. L’inconvénient des enregistrements sonores est qu’ils nécessitent beaucoup de travail (et donc un investissement financier conséquent) avant d’être utilisables pour la recherche scientifique. Heureusement, la situation a changé il y a quelques années: un groupe de linguistes de l’UGent a conjugué ses efforts pour redonner vie aux voix du passé, grâce au Corpus oral des dialectes des Pays-Bas méridionaux (GCND, «Gesproken Corpus van de zuidelijk-Nederlandse Dialecten») (1).
De bons narrateurs, âgés et peu instruits
Dans les années 1960, le professeur Valeer Frits Vanacker lance un projet de grande envergure. Il s’agit de l’enregistrement sur cassette de tous les dialectes locaux de la Belgique néerlandophone et de la Flandre française (et plus tard de la Flandre zélandaise). L’idée était la suivante: un locuteur très constant dans l’usage de son dialecte s’exprime librement dans une conversation spontanée d’environ 48 minutes, soit la durée d’une bande sonore sur les magnétophones Revox utilisés. Cette durée devait permettre de documenter les principaux phénomènes phonologiques d’un lieu géographique spécifique.
 Valeer Frits Vanacker était un des pionniers de l'étude de la syntaxe dialectale dans les Plats Pays.
Valeer Frits Vanacker était un des pionniers de l'étude de la syntaxe dialectale dans les Plats Pays.Vanacker, qui est l’un des pionniers de l’étude de la syntaxe dialectale dans les Plats Pays, espérait en outre que ce matériel lui permettrait d’étudier les phénomènes syntaxiques propres à la langue spontanée. En comparaison avec le vocabulaire, la syntaxe se laisse moins facilement documenter à l’aide de questionnaires. De plus, les enregistrements de la parole spontanée permettent de vérifier dans quelles proportions sont utilisées certaines structures concurrentes.
Les informateurs devaient répondre à un certain nombre de critères. Ils devaient non seulement être de bons narrateurs, mais aussi, de préférence, être âgés et peu instruits. Dans les années 1960 et 1970, l’on s’était en effet rendu compte de l’inévitable modification, voire disparition des dialectes ancestraux en raison de la scolarisation accrue de la population, l’influence des médias (journaux, radio et télévision) et l’augmentation de la mobilité sociale et géographique. En outre, l’informateur devait avoir quitté sa commune le moins possible et ses deux parents, tout comme son éventuel(le) partenaire, devaient être originaires de cette même commune.
Ces critères ont orienté les chercheurs principalement vers la population paysanne dans les zones rurales et vers la classe ouvrière dans les villes. Leurs informateurs correspondaient à un type de personne devenu très rare aujourd’hui: quelqu’un qui n’avait tout simplement pas d’autre registre linguistique que son dialecte local. Une personne âgée d’environ 80 ans dans les années 1960-1970 était née vers 1880, c’est-à-dire environ 30 ans avant l’introduction de l’enseignement obligatoire en 1914 (du moins en Belgique).
Des conversations spontanées
Afin de garantir la spontanéité maximale de la conversation, les enregistrements étaient effectués au domicile des locuteurs et réalisés par le biais d’un intermédiaire. Cette personne non seulement connaissait l’informateur et avait généralement proposé sa participation, mais elle dirigeait aussi la conversation, tandis qu’un technicien (souvent le chercheur lui-même) s’occupait des aspects techniques dans une autre pièce.
Cela permettait d’éviter l’ainsi appelé «paradoxe de l’observateur», c’est-à-dire une situation où le chercheur, dans sa recherche de matériel linguistique spontané, perturbe lui-même le caractère spontané par sa présence. Les enregistrements à domicile présentaient cependant aussi des inconvénients. La conversation était ainsi souvent perturbée par des bruits de fond tels que des tic-tac d’horloge, le cliquetis de casseroles ou le chien de la maison.
Certains enregistrements proviennent de villages ou hameaux qui n’existent plus aujourd’hui, comme Lillo, Oorderen et Wilmarsdonk qui ont dû céder la place à l'expansion du port d'Anvers dans les années 1960
Le tout premier enregistrement de la collection a été réalisé à Dikkebus le 29 mars 1961. La collection s’est ensuite développée lentement. Au début, il y avait en effet peu de fonds pour couvrir les frais de voyage et les professeurs devaient souvent être présents à l’université. Qui plus est, de nombreux informateurs «idéaux», en particulier des agriculteurs, n’avaient pas le temps pendant les mois d’été, car ils travaillaient dans leurs champs. 783 cassettes audio ont malgré tout été enregistrées dans 550 lieux différents.
Plusieurs enregistrements ont été effectués au même endroit. C’était le cas lorsqu’ils étaient liés à un mémoire de licence. Les recherches des étudiants portaient souvent sur plusieurs générations et leurs enregistrements documentaient par conséquent des locuteurs d’âges différents. Certains locuteurs étaient originaires de villages ou de hameaux qui n’existent plus aujourd’hui, comme les villages disparus des polders de Lillo, Oorderen et Wilmarsdonk, qui ont dû céder la place à l’expansion du port d’Anvers dans les années 1960.
© DR
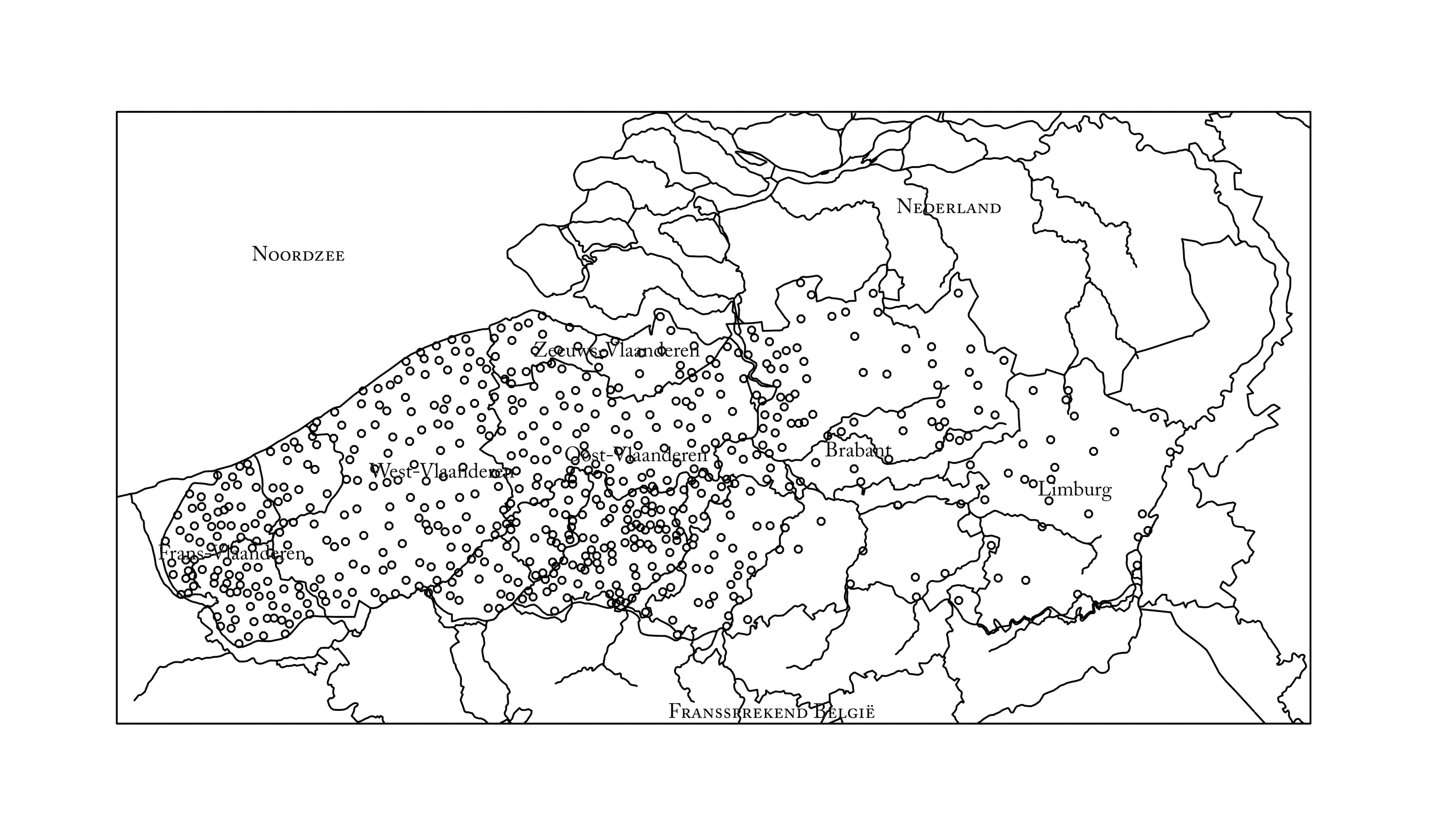
En observant sur une carte la répartition des enregistrements sonores, on constate que la Flandre-Orientale et la Flandre-Occidentale sont les plus fortement représentées dans la collection. Les chercheurs gantois recrutaient en effet souvent les intermédiaires parmi leurs étudiants en néerlandais et la population étudiante gantoise était principalement issue de ces deux provinces.
Flandre française a fait l’objet d’un effort particulier. En partant de l’idée que le dialecte flamand ne survivrait pas longtemps dans cette région, l’équipe a voulu réaliser un enregistrement dans chaque village où le néerlandais était encore parlé (2). Pour la Flandre zélandaise, le professeur Johan Taeldeman s’est engagé à réaliser le plus grand nombre d’enregistrements possible.
Le thème de la conversation était en principe totalement libre. Dans la pratique, toutefois, il était tout de même quelque peu dirigé. Les agriculteurs étaient ainsi priés d’expliquer les techniques agricoles anciennes, les personnes aux professions devenues rares (vanniers, tonneliers…) parlaient de leur métier, les vétérans commentaient la Première et la Seconde Guerre mondiale, de nombreux informateurs avaient vécu l’apparition des premières bicyclettes, des voitures, de la radio, de l’électricité, de la télévision, etc.
La collection ne reflète donc pas seulement les dialectes traditionnels, mais constitue aussi la plus grande collection de récits de vie de Flamands peu alphabétisés du XXe siècle. Grâce à ces témoignages uniques sur la vie d’antan, la collection a aussi une grande valeur ethnographique, en plus de sa valeur linguistique.
Numériser et rendre accessible: le corpus oral des dialectes des Pays-Bas méridionaux (GCND)
Il va sans dire que l’ère numérique offre de nouvelles opportunités permettant de rendre la collection accessible de manière efficace. La numérisation des enregistrements sur bande sonore a commencé dès le début du XXIe siècle sous la direction du professeur Johan Taeldeman. Depuis, l’ensemble des extraits sonores peut être consulté sur le site web www.dialectloket.be (une initiative du professeur Jacques Van Keymeulen, avec des remerciements au recteur honoraire Paul Van Cauwenberge qui a joué un rôle de médiateur pour l’obtention d’un financement en 2009).
Toutefois, en vue d’un accès maximal, la seule numérisation ne suffit pas. Linguistes et ethnographes doivent avoir la possibilité de chercher des mots, des structures de phrases ou des thèmes spécifiques sans avoir à écouter tous les enregistrements dans leur intégralité. Dans cette optique, il était nécessaire que les bandes sonores soient transcrites. Les premiers pas dans cette direction ont été faits dès les années 1960 et 1970. Des étudiants ont alors transcrit une partie des enregistrements (318 au total) en fonction d’un protocole de transcription très basique.
© UGent
Plus tard, en 2019, un financement (3) provenant de différents canaux a permis de lancer un projet visant non seulement la transcription uniforme de l’ensemble de la collection, mais aussi le comblement de ses lacunes. Pour atteindre ce dernier objectif, de nouveaux enregistrements ont été réalisés dans le Brabant flamand et au Limbourg, bien qu’il n’ait pas été facile de trouver des interlocuteurs qui répondent encore aux critères de sélection initiaux.
De plus, grâce à des contacts avec l’Institut Meertens d’Amsterdam, l’équipe gantoise a eu accès à des enregistrements sonores de dialectes zélandais, du Brabant-Septentrional et du Limbourg provenant de la base de données des dialectes des Pays-Bas (Nederlandse Dialectenbank). Cette coopération a permis de créer une base de données –ou un corpus, comme on l’appelle en linguistique– documentant l’ensemble de l’aire dialectale des Pays-Bas méridionaux.
La transcription est un travail chronophage: en moyenne, un transcripteur a besoin d'une heure pour traiter 200 secondes de son dialectal
Dans un premier temps, la transcription des enregistrements compilés se fait entièrement manuellement (4) et à deux niveaux: une première transcription proche du dialecte et une autre plus proche du néerlandais standard. Cette dernière transcription est nécessaire, entre autres, pour rendre les textes numériques accessibles aux chercheurs qui ne parlent pas le dialecte en question.
Les transcriptions sont réalisées à l’aide du logiciel open source ELAN et alignées sur la source audio, permettant ainsi une vérification à tout moment. Il va sans dire qu’une telle méthode de travail est chronophage: en moyenne, un transcripteur a besoin d’une heure pour traiter 200 secondes de son dialectal.
Les transcripteurs –sauf pour les enregistrements provenant de la Flandre française– sont des étudiants jobistes. Ils doivent surmonter deux types de problèmes: d’une part, ils ne comprennent pas toujours très bien les dialectes très archaïques (même s’ils se considèrent encore comme des locuteurs du dialecte), et d’autre part, ils sont complètement étrangers à l’univers des locuteurs. Chaque transcription est donc relue par des bénévoles plus âgés et compétents en matière de dialectes.
Dans un deuxième temps, les transcriptions sont complétées avec des annotations de nature linguistique identifiant les classes de mots (part-of-speech tagging) et les structures syntaxiques (parsing). Cela doit permettre de consulter la collection non seulement sur le plan lexical, mais aussi sur le plan plus abstrait des structures de phrase. Par exemple, si un locuteur dit «ik kom!» («J’arrive!»), il est ajouté à ce fragment de transcription qu’il s’agit d’une succession d’un pronom et d’un verbe, lesquels fonctionnent sur le plan syntaxique respectivement comme sujet et comme tête de phrase.
La transcription «vers le néerlandais» permet la réalisation automatique de cet étiquetage dans un premier temps, à l’aide d’un logiciel disponible pour le néerlandais standard (des outils spécifiques adaptés au matériel dialectal n’existent pas encore). Cela n’exclut pas pour autant la nécessité de vérifications manuelles par la suite.
Afin de rendre disponible le contenu de la base de données GCND pour la recherche ethnographique, des bénévoles ont rédigé des résumés de chaque enregistrement sonore (voir www.dialectloket.be). Récemment, grâce à des financements de l’UGent, les enregistrements ont été annotés thématiquement à l’aide d’un inventaire uniforme de mots-clés. Cela permet des sélections et des recherches thématiques. Par exemple, en introduisant le mot-clé «Seconde Guerre mondiale» sur Dialectloket, le programme sélectionne les passages dans lesquels ce sujet est abordé; plus besoin de parcourir des bandes sonores dans leur intégralité.
Des voix en dialectes de toute l’aire néerlandophone
Rendre accessible la collection, tant sur le plan linguistique que sur celui du contenu, est un travail de longue haleine, mais qui porte ses fruits. Depuis le 24 octobre 2024, la consultation linguistique de la collection est possible via le site web de l’Institut de la langue néerlandaise (INT) de Leyde, qui est responsable de l’hébergement.
L’application de l’Institut s’adresse dans un premier temps aux chercheurs souhaitant consulter la collection pour des analyses linguistiques par le biais des options de recherche. Les personnes intéressées qui ne sont pas liées à un institut de recherche peuvent également obtenir l’accès.
Ceux qui souhaitent surtout écouter les enregistrements (avec les transcriptions comme sous-titres) ou rechercher des passages sur des thèmes spécifiques, peuvent visiter le site web en libre accès www.dialectloket.be.
Autre bonne nouvelle: l’équipe du GCND va étendre son projet au reste des Pays-Bas grâce à un financement supplémentaire. À l’avenir, le corpus comprendra donc des voix dialectales de langue néerlandaise venant de l’ensemble de la région européenne.
Notes
1. Le terme linguistique corpus désigne une «collection systématique de textes pour la recherche linguistique».
2. Le musée de Flandre à Cassel a reçu une copie de la version numérique des enregistrements réalisés en Flandre française.
3. Le financement total du projet a été réalisé grâce aux canaux suivants: 2020-2024: Infrastructure de recherche de taille moyenne FWO [le Fonds flamand pour la Recherche Scientifique] I.0.101.20N
2018-2020: Fonds de recherche FWO 1.5.310.18N pour A. Breitbarth (projet pilote)
2018-2021: Mandat postdoctoral junior FWO 1.2.P79.19N pour M. Farasyn (enregistrements de la Flandre française)
2021-2024: Mandat postdoctoral senior FWO 1.2.P79.22N pour M. Farasyn (enregistrements de la Flandre française)
2019-2021: Subsides venant des provinces de Zélande, de Flandre-Occidentale et de Flandre-Orientale (projet pilote)
4. Au début du projet, la reconnaissance automatique de la parole n’était pas encore suffisamment avancée pour les dialectes parlés, rendant impossible la transcription (semi-)automatique des enregistrements. Toutefois, des progrès significatifs ont été réalisés dans ce domaine au cours des dernières années. C’est pourquoi l’équipe du projet collabore actuellement avec des technologues du langage de la KU Leuven pour déterminer dans quelle mesure le processus de transcription peut être accéléré par le biais de la reconnaissance automatique de la parole.





Commentaires
Laisser un commentaire
Vous devez vous connecter pour publier un commentaire.
Lisez aussi




Tout cela est très intéressant mais il ne faut pas oublier que le Traité de Courtrai du 28 mars 1820 fixe définitivement l’actuelle frontière. Rechercher des locuteurs néerlandophones, même patoisant, par-delà la frontière française relève d’un état d’esprit millénaire, germanique, d’entrevoir une possibilité de démembrer le voisin. « Ce qui est moi, m’appartient. Ce qui est toi, se discute. »